An Actor-Critic Architecture with
Reward and Punishment
Reward and punishment are often seen as opposite values on the same dimension. This is especially true for reinforcement learning where reward is often represented by positive reinforcement values, while punishment is represented by negative values. Although such a view of reward and punishment may be useful in many cases, it ignores the fundamental difference in how it is appropriate to react to the two types of situation.
It is useful to distinguish between passive and active avoidance. Active avoidance is the situation when it is necessary to try to escape, for example when being chased by a predator. Passive avoidance on the other hand does not necessarily require any action. All we need to do is avoid doing something dangerous, such as avoiding running over a cliff.
For appetitive learning, it is useful to be able to generalize to new similar situation. If one situation or action has proved to be rewarding, it is useful to try out similar actions in the future to explore if they too will result in a reward. The appetitive part of a learning system should thus maximally generalize previously learned behaviors to new situations. To make this possible, it is necessary that the coding of the current situation or state contains sufficient information to support generalization. However, a maximally generalizing system will obviously overextend its behavior to situations were they are not appropriate. Context provides a mean to greatly reduce the number of incorrect generalization, making it easier to separate the relevant information about a given situation. Context can be thought of as any information that can be used to characterize the situation, such as the task, question, place or even the goal. Studies made on animals suggest that a behavior learned in one context is carried over to other contexts, but learned inhibition of a behavior will be unique to each context where the behavior was extinguished. Most reinforcement learning algorithms learn to complete a single task in one context, but animals apply what they learn in one context to other contexts as well.
The solution we propose is to divide the input into one focal part, which can be seen as the attended part of the environment, and a contextual part, which codes for the situation. The focal part is used to control actions by being directly associated with behaviors while the contextual part is used to select between different possible behaviors. Previous studies have shown that it is possible to construct a context sensitive artificial neural network that fulfills these demands, while simultaneously avoiding catastrophic forgetting. It has been used to model context sensitive categorization , task-switching and developmental disorders. We recently tested this type of mechanism within a Q-learning framewor. Here, we develop these ideas further and implement context sensitivity in an actor-critic framework. In addition, we investigate how punishment can be included to speed up learning.
Overview of the System
The general reinforcement learning framework illustrated in Fig. 1 was used for all the simulations and implemented in the Ikaros system. A simpler version of this framework has been previously described by Winberg, and it is here extended by the addition of an actor and critic and a dedicated punishment system. The extended framework consists of the five main modules ACTOR, CRITIC, PUNISH, RL-CORE, and SELECT.
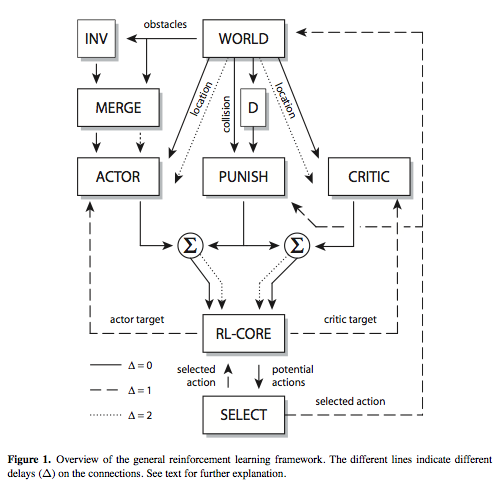
Main Modules
The module ACTOR is responsible for action selection in each state. It has three inputs and one output. One input-output pair is used to calculate the expected value of each possible action in the current state. The other two inputs are used to train the module on the mapping from a state delayed by two time steps to a target delayed by one time step. Any of a number of algorithms can be used as ACTOR, ranging from tables to different types of function approximators and artificial neural networks. Because of the separate input for training and testing, the module ACTOR can simultaneously work in two different time frames without the need to know about the timing of the different signals. Here we use the context sensitive function approximator we have previously developed .
The module CRITIC is used to estimate the expected value of an action a in each state. Learning is dependent on the current policy of the ACTOR module and the CRITIC module must learn to evaluate the actions of the ACTOR module. Just like the ACTOR module, the CRITIC module has three inputs and one output. The inputs are separate for training and testing but receive the same data. The function is similar to the ordinary implementation of actor-critic architectures.
The purpose of the module PUNISH is to learn weather or not any of the surrounding states of the current state is inaccessible. That is, if action a in state s will lead to the return to the same state or not. How this is done is often rather specific to the task at hand but can usually be done by analyzing the state and action vectors of previous time steps to see if the selected action caused a state change or not. If not, a negative association is formed between state and action which will greatly reduce the risk of repeating this behavior. The learning in the PUNISH module is driven by the collision signal from the environment. This signal is active each time the agent tries to move into a wall. When the PUNISH module receives a collision signal, it will learn to associate the attempted action in the current situation with punishment, which reduces its likelihood in the future. Since the state is coded in a way that allows generalization of punishment to other identical situations, the agent will rapidly learn to not try to move into obstacles.
The module RL-CORE is the reinforcement learning specific component of the system. This module receives information about the current state in the world, the current reinforcement, the action selected at the previous time step and data from both the ACTOR and CRITIC module in the current state. This is used to calculate the training target for the ACTOR and CRITIC modules. The target vectors are both equal to the input vector of the CRITIC from the last time step, but for the ACTOR module's target vector, the value of the action selected the last time step is replaced with the maximum discounted action value received from the CRITIC in the current time step. For the target vector of the CRITIC module, the incoming reinforcement signal is used.
The module SELECT performs action selection based on its input from RL-CORE. It may also potentially have other inputs that determine what action is selected. This module may for example implement Boltzmann selection or ε-greedy selection. It may also use different forms of heuristics to select an action. It is even possible that the action selected is entirely independent of the inputs from RL-CORE. In this case, RL-CORE will learn the actions performed by some other subsystem.
All communication between the different modules consists of numerical matrices. The connections may optionally delay the signal by one or several time steps (Fig. 1). One advantage of this framework is that the different modules can be exchanged to build different forms of reinforcement learning systems. Another advantage is that all timing is taken care of by the delays on the connections between the different modules. If the world is slower at producing the reward, the only things that need to be changed are the different delays in the system.
Coding
An important part of the architecture is its ability to handle generalization in different ways in different parts of the system. The ACTOR, CRITIC and PUNISH modules all receive input about the current state of the world, but they are coded in different ways to support different forms of generalizations.
The information about obstacles around the current location in the world consists of a binary matrix with 1 for obstacles and 0 for open space. This matrix is inverted (INV) and merged (MERGE) with the original representation to form vector with a dual coding of the surrounding around the agent. The resulting vector is given as input to the ACTOR. This coding makes it easy for the actor to generalize actions to new situations since this input contains information that lets the actor learn about the actions that are possible in each state. In addition, the ACTOR module also receives location input from the world that is used for contextual inhibition.
The CRITIC does not use the focal information about obstacles around the agent. Instead, it uses the location code to learn the value for each location in the environment. This is the most suitable information for learning the shortest path through an environment.
Finally, the PUNISH module uses another coding of the surrounding around the agent. The binary pattern with nine elements is `decoded' into one of 512 distinct vectors with a single 1 at one position and 0 at the others. This decoding is used as a simplified means of getting distinct categories for environments where the agent has received punishment. In practice, all the different categories are not used, and it would be possible to dynamically create the required categories instead, but here we have opted for the simplest solution.
The results of using this architecture on different maze learning tasks were presented in the paper "Fast Learning in an Actor-Critic Architecture with Reward and Punishment" by Balkenius and Winberg presented ad SCAI 2008.
Bibliography
Balkenius, C. (1995). Natural intelligence in artificial creatures. Lund University Cognitive Studies, 37.
Balkenius, C. (1996). Generalization in instrumental learning. In Maes, P., Mataric, M., Meyer, J.-A., Pollack, J., and Wilson, S. W. (Eds.), From Animals to Animats 4: Proceedings of the Fourth International Conference on Simulation of Adaptive Behavior. Cambridge, MA: MIT Press.
Balkenius, C., and Morén, J. (2000). A computational model of context processing. In Meyer, J-A., Berthoz, A., Floreano, D., Roitblat, H. L., Wilson, S. W. (Eds.), From Animals to Animats 6: Proceedings of the 6th International Conference on the Simulation of Adaptive Behaviour. Cambridge, MA: MIT Press.
Balkenius, C., Morén, J. and Johansson, B. (2007). System-level cognitive modeling with Ikaros. Lund University Cognitive Studies, 133.
Balkenius, C. and Winberg, S. (2004). Cognitive Modeling with Context Sensitive Reinforcement Learn- ing, Proceedings of the AILS-04 Workshop, 10-19.
Balkenius, C. and Winberg, S. (2008). Fast Learning in an Actor-Critic Architecture with Reward and Punishment, In A. Holst, P. Kreuger and P. Funk (Eds) Tenth Scandinavian Conference on Artificial Intelligence (SCAI 2008) (pp. 20-27). Frontiers in Artificial Intelligence and Applications, 173. IOS Press. ISBN: 978-1-58603-867-0.
Björne, P., and Balkenius, C. (2005). A model of attentional impairments in autism: First steps toward a computational theory. Cognitive Systems Research, 6, 3, 193-204.
Barto, A. G., Sutton, R. S. and Anderson, C. W. (1983) Neuronlike adaptive elements that can solve difficult learning control problems. IEEE Transactions on Systems, Man, and Cybernetics 13:835-846.
Bouton, M. E. (1991). Context and retrieval in extinction and in other examples of interference in simple associative learning. In Dachowski, L. W. and Flaherty, C. F. (Eds.), Current topics in animal learning: Brain, emotion, and cognition (pp. 25Ð53). Hillsdale, NJ: Erlbaum.
French, R. M. (1999). Catastrophic Forgetting in Connectionist Networks. Trends in Cognitive Sciences, 3, 128-135.
Hall, G. (2002) Associative Structures in Pavlovian and Instrumental Conditioning In Pashler, H. and Gallistel, R. (eds.), Steven's Handbook of Experimental Psychology. Volume 3: Learning, Motivation, and Emotion. John Wiley & Sons.
Koenig, S. and Simmons, R.G. (1996).The Effect of Representation and Knowledge on Goal-Directed Exploration with Reinforcement-Learning Algorithms. Machine Learning, 22, (1-3), 227-250.
Morén, J. (2002). Emotion and Learning - A Computational Model of the Amygdala, Lund University Cognitive Studies, 93.
Sutton, R., and Barto, A., (1998). Reinforcement Learning: An Introduction. MIT Press, Cambridge, MA, A Bradford Book.
Watkins, C. J. C. H. and Dayan, P. (1992). Q-learning. Machine Learning, Vol. 9, 279-292. [15] Winberg, S. (2004). Contextual Inhibition in Reinforcement Learning, MSc Thesis in Cognitive Science. Lund University.
Winberg, S. and Balkenius, C. (2007). Generalization and Specialization in Reinforcement Learning. In Berthouze, L. et al., Proceedings of the seventh international conference on Epigenetic Robotics. Lund University Cognitive Studies, 135.